深入浅出dpdk: cache与内存¶
本文更新于 2018.09.27
内存Cache简介¶
存储系统架构¶
NUMA系统中的内存结构:
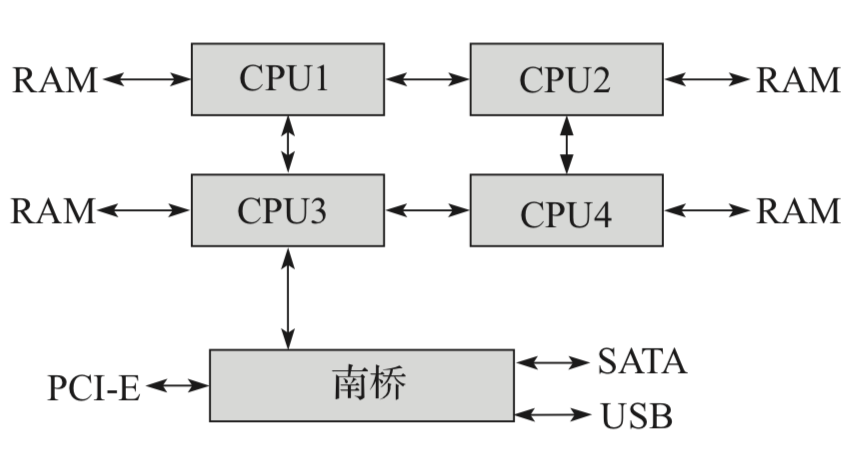
内存和Cache是重要的存储系统, 其中内存目前使用DDR, Cache使用SRAM. SRAM速度很快, 但容量小, 成本很高; DDR速度慢, 但容量很大.
小技巧
- RAM: Random Access Memory, 随机访问存储器
- SRAM: Static RAM, 静态随机访问存储器
- DRAM: Dynamic RAM, 动态随机访问存储器
- SDRAM: Synchronous DRAM, 同步动态随机访问存储器
- DDR: Double Data Rate SDRAM, 双数据速率SDRAM
- DDR2, DDR3, DDR4 ...
处理器直接访问内存非常慢, 大概需要几百个时钟周期, 而在这期间处理器只能等待. 为了解决这个问题,提出了Cache的概念. Cache一般集成在处理器内部, 处理器对它的访问速度远远快于外部内存.
Cache种类¶
目前Cache主要由三级组成: L1 Cache, L2 Cache和Last Level Cache(LLC). L1最快, 但容量小, 可能只有几十KB; LLC慢, 但容量大, 可能多达几十MB. L1和L2 Cache一般集成在CPU内部. 另外, L1和L2 Cache是每个处理器核心独有的 , 而LLC是被所有核心所共享的.
Intel处理器对各级Cache的访问时间一直都保持稳定, 见下表所示:
| Cache级别 | cycle数 |
|---|---|
| L1 | 4 |
| L2 | 12 |
| LLC | 26~31 |
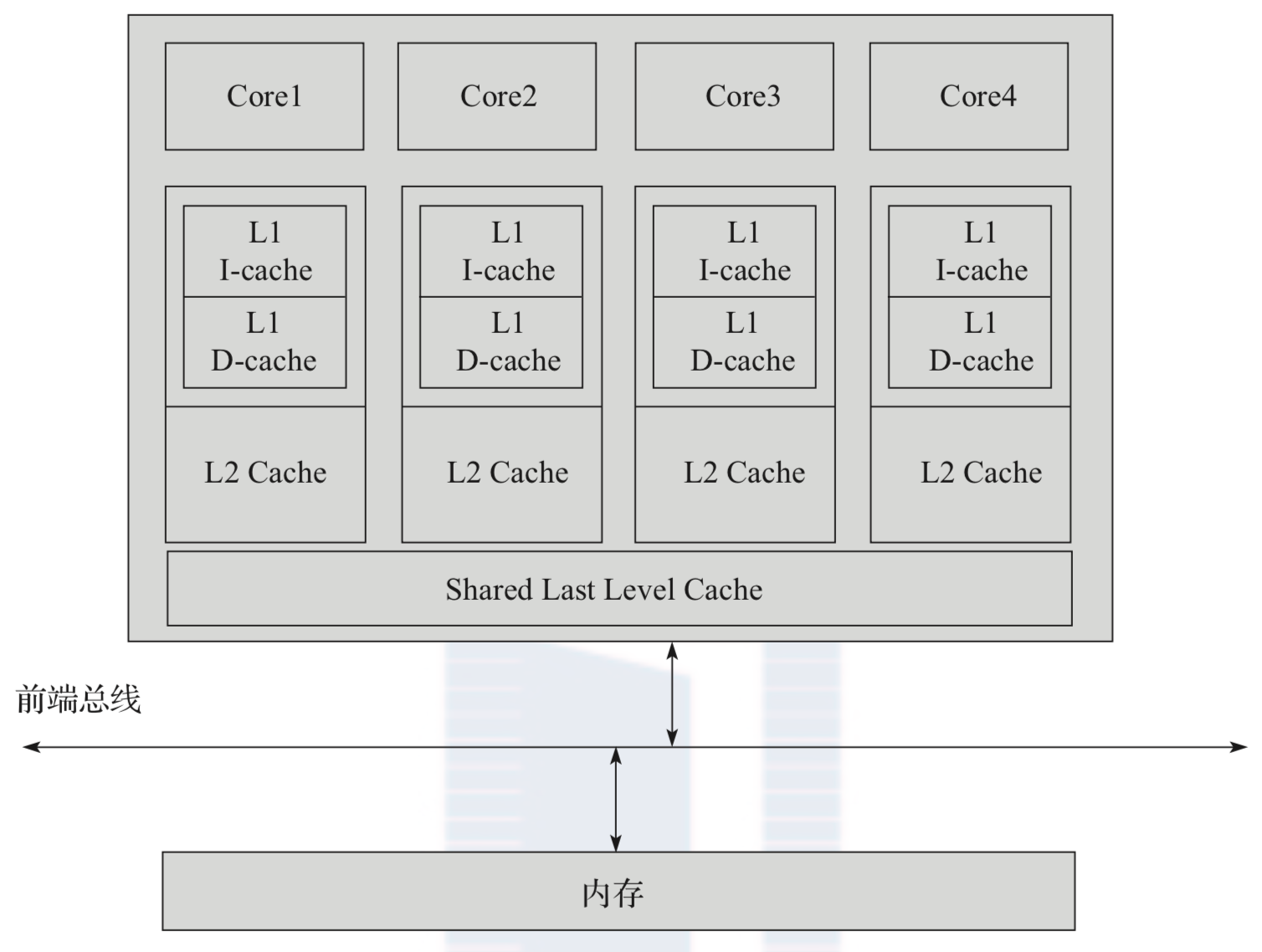
除以上Cache外, 现代CPU中还有一个TLB (Translation Look-aside Buffer) Cache, 专门用于缓存内存中的页表项. TLB Cache使用虚拟地址进行搜索, 直接返回对应的物理地址, 相对于内存中的多级页表需要多次访问才能得到最终物理地址, TLB查找大大减小了处理器的开销.
Cache地址映射与变换¶
内存容量很大, 一般是GB级, 而Cache最大才几十MB. 要把内存数据放到Cache中, 需要一个分块机制和映射算法.
Cache和内存以块为单位进行数据交换, 块的大小通常以在内存的一个存储周期内能够访问到的数据长度为限, 当前主流块的大小为64字节, 这也就是Cache line的含义.
而映射算法分为全关联型, 直接关联型和组关联型3种, 具体机制在此不赘述. 目前广泛使用组关联型Cache.
Cache的写策略¶
内存的数据被加载到Cache后, 在某个时刻要被写回内存, 写回策略有以下几种:
直写(write-through)处理器写入Cache的同时, 将数据写入内存中.回写(write-back)为cache line设置dirty标志, 当处理器改写了某个cache line后, 不立即将其写回内存, 而是将dirty标志置1; 当处理器再次修改该cache line并且写回cache中, 查表发现dirty=1, 则先将cache line内容写回内存, 再将新数据写到cache.WC(write-combining)当cache line的数据被批量修改后, 一次性将其写到内存.UC(uncacheable)针对内存不能被缓存到cache的场景, 比如硬件需要立即收到指令.
Cache预取¶
预取原理¶
cache底层如何动作, 对程序员来说透明的, 但一些体系架构提供了能够对cache进行预取的指令, 从而使程序员可以在一定程度上控制cache, 加快程序的运行.
cache之所以能够提高系统性能, 主要原因是程序运行存在局部性现象, 包括时间局部性和空间局部性. 这两种情况下处理器会把之后要用到的指令/数据读取到cache中, 提高程序性能. 而所谓的cache预取, 就是预测哪些指令/数据将会被用到, 然后采用合理方法将其预先取入到cache中.
下面两段代码A和B都是给2维数组赋值, 但执行效率相差很多, 因为代码A对于数组是顺序访问, 会利用cache硬件预取特性将后续要用到的数据读入cache, 提升性能; 而代码B是跳跃式访问, 硬件无法预取, 需要频繁访问内存, 降低性能.
// A
for(i=0; i<COUNT; i++)
{
for (j=0; j<COUNT; j++)
{
arr[i*COUNT + j] = num++;
}
}
// B
for(i=0; i<COUNT; i++)
{
for (j=0; j<COUNT; j++)
{
arr[j*COUNT + i] = num++;
}
}
小技巧
以上代码需要非优化编译才可以看到效果, 如果加了-O2等优化选项, 则编译器会对代码进行优化, 无法看出性能差异.
软件预取指令¶
一些处理器提供的软件预取指令(只对数据有效):
- PREFETCH0 将数据存放在所有cache
- PREFETCH1 将数据存放在L1 Cache之外的cache
- PREFETCH2 将数据存放在L1, L2 Cache之外的cache
- PREFETCHNTA 与PREFETCH0类似, 但数据是以非临时数据存储, 在使用完一次后, cache认为该数据是可以被淘汰出去的
这些指令都是汇编指令, 一些程序库会提供对应的C语言版本, 如mmintrin.h中的_mm_prefetch()函数:
// p: 要预取的内存地址
// i: 预取指令类型, 与汇编指令对应关系如下
// _MM_HINT_T0: PREFETCH0
// _MM_HINT_T1: PREFETCH1
// _MM_HINT_T2: PREFETCH2
// _MM_HINT_NTA: PREFETCHNTA
void _mm_prefetch(char* p, int i);
dpdk中的预取¶
dpdk转发一个报文所需要的基本过程分解:
- 写接收描述符到内存, 填充数据缓冲区指针, 网卡收到报文后就会根据这个地址把报文内容填充进去.
- 从内存中读取接收描述符(当收到报文时, 网卡会更新该结构)(内存读), 从而确认是否收到报文.
- 从接收描述符确认收到报文时, 从内存中读取控制结构体的指针(内存读), 再从内存中读取控制结构体(内存读), 把从接收描述符读取的信息填充到该控制结构体.
- 更新接收队列寄存器, 表示软件接收到了新的报文.
- 内存中读取报文头部(内存读), 决定转发端口.
- 从控制结构体把报文信息填入到发送队列发送描述符, 更新发送队列寄存器.
- 从内存中读取发送描述符(内存读), 检查是否有包被硬件传送出去.
- 如果有的话, 从内存中读取相应控制结构体(内存读), 释放数据缓冲区.
可以看出, 处理一个报文的过程, 需要6次读取内存(见上“内存读”).而之前我们讨论过 处理器从一级Cache读取数据需要3~5个时钟周期, 二级是十几个时钟周期, 三级是几十个时钟周期, 而内存则需要几百个时钟周期. 从性能数据来说, 每80个时钟周期就要处理一个报文.
因此, dpdk必须保证所有需要读取的数据都在Cache中, 否则一旦出现Cache不命中, 性能将会严重下降.为了保证这点, dpdk采用了多种技术来进行优化, 预取只是其中的一种.
而从上面的介绍可以看出, 控制结构体和数据缓冲区的读取都没有遵循硬件预取的原则, 因此dpdk必须用一些预取指令来提前加载相应数据. 以下就是部分接收报文的代码.
while (nb_rx < nb_pkts) {
rxdp = &rx_ring[rx_id]; // 读取接收描述符
staterr = rxdp->wb.upper.status_error;
// 检查是否有报文收到
if (!(staterr & rte_cpu_to_le_32(IXGBE_RXDADV_STAT_DD)))
break;
rxd = *rxdp;
// 分配数据缓冲区
nmb = rte_rxmbuf_alloc(rxq->mb_pool); nb_hold++;
// 读取控制结构体
rxe = &sw_ring[rx_id];
......
rx_id++;
if (rx_id == rxq->nb_rx_desc)
rx_id = 0;
// 预取下一个控制结构体mbuf
rte_ixgbe_prefetch(sw_ring[rx_id].mbuf);
// 预取接收描述符和控制结构体指针
if ((rx_id & 0x3) == 0) {
rte_ixgbe_prefetch(&rx_ring[rx_id]);
rte_ixgbe_prefetch(&sw_ring[rx_id]);
}
......
// 预取报文
rte_packet_prefetch((char *)rxm->buf_addr + rxm->data_off);
// 把接收描述符读取的信息存储在控制结构体mbuf中
rxm->nb_segs = 1;
rxm->next = NULL;
rxm->pkt_len = pkt_len;
rxm->data_len = pkt_len;
rxm->port = rxq->port_id;
......
rx_pkts[nb_rx++] = rxm;
}
警告
这段代码需要结合实际源码深入理解
Cache一致性¶
// cache line对齐
// cache一致性问题的根源, 是因为存在多个处理器核心各自独占的cache(L1,L2), 当多个核心访问内存中同一个cache行的内容时, 就会因为多个cache同时缓存了该内容引起同步的问题.
dpdk的解决方案是避免多个核心访问同一个内存地址或者数据结构. 如果有多个核需要同时访问同一个网卡, dpdk会给每个核都准备一个单独的接收队列/发送队列.
DDIO¶
Intel DDIO(Direct Data I/O)技术使网卡和CPU通过LLC Cache直接交换数据, 绕过了内存这个相对慢速的部件, 减少了处理器和网卡访问内存的次数, 也减少了Cache写回的等待, 提高了 系统的吞吐率和数据的交换延迟.
NUMA系统¶
// SMP与NUMA系统示意图
与SMP系统相比, NUMA系统访问本地内存的带宽更大, 延迟更小, 但是访问远程内存的成本很高, 因此要充分利用NUMA系统的这个特点, 避免远程访问资源.
dpdk对于NUMA系统的一些优化:
- pre-core memory. 每个核心都有属于自己的内存, 一方面是为了访问本地内存, 另一方面也达成了Cache一致性
- 本地设备本地处理. 即用本地的核心, 本地的内存来处理本地的网卡