CPU Cache Optimization¶
本文更新于2019.04.24
本文主要译自Rogue Wave Software公司的一篇文章, 并对示例代码进行了运行验证.
目录
做为开发者, 我们非常熟悉cache的概念. 操作系统, 数据库, 文件系统, 甚至我们自己开发的软件, 都会使用某种形式的cache. 那么现代处理器中的CPU cache呢? 它有什么不同?
如果你没有关心过内存cache对代码的影响, 那么你必须得读完本文. 本文并不深入描述现代处理器, 而是用几个cache优化示例来帮助你了解”CPU cache优化”技术.
不管你的程序如何, cache都会自动运行. 不过, 问题在于: 如果以某种可以优化cache访问的方式编写程序, 它的性能会提升多少? 对服务器的需求会减少几台? 它需要上百万美元的IT预算吗?
CPU Cache: the Need to Know¶
cache用于把频繁用到的数据保持在可用和易于访问的状态, 从而提升程序整体性能. 不同内存层次的访问开销如下表所示:
| 内存层次 | 相对延迟 |
|---|---|
| L1 Cache | 1x |
| Higer Cache Levels | 10x |
| Main Memory | 100x |
来源: AMD, Michael Wall
这意味着使用已经在L1 cache中的数据要比从主存中取数据快100倍. 这并不意味着优化后你的程序可以快100倍, 而是给了我们在何处进行优化的提示. 但问题还在, (优化后)究竟能快多少? 来考虑一个例子.
Our First Example¶
让我们来比较下面两段相似的C++代码, Program A和Program B. 唯一的不同是结构体的定义, Program A中结构体有两个无用的成员c和d:
1 2 3 4 5 6 7 8 9 10 11 12 | struct DATA
{
int a;
int b;
int c;
int d;
};
DATA *pMyData;
for (long i=0; i<10*1024*1024; i++) {
pMyData[i].a = pMyData[i].b;
}
|
1 2 3 4 5 6 7 8 9 10 | struct DATA
{
int a;
int b;
};
DATA *pMyData;
for (long i=0; i<10*1024*1024; i++) {
pMyData[i].a = pMyData[i].b;
}
|
看过这两段代码似乎可以推断它们的性能没有区别: 它们的处理逻辑完全相同, 而且现代编译器也没有理由不把其中的循环语句生成相同的二进制代码. 在一台小PC(Windows 7系统, U9400@1.40Ghz双核CPU)上, 打开编译器完全优化, 编译运行这两段代码, 结果如下:
- Program A执行时间0.16秒
- Program B执行时间0.08秒
Program B居然比A快一倍! 让我们研究一下这背后发生了什么.
Cache Line and Fetch Utilization¶
开发者经常做一个假定: 当向cache取一个”int”时, 会从内存拷贝32bit到CPU cache. 然而, CPU cache不是这样处理数据的, 它会以固定大小的”块”来存取内存. 不论你取一个bit, 一个”int”或一个”long”, 现代CPU如Intel Core2 Duo不仅会取你要的数据, 而且还会取它附近共64字节的数据. 这称为”cache line”, 典型的cache line大小是64字节.
回顾Program A, 它所用数据的内存布局如下图所示:

Program A的一个完整的cache line. 每个方块表示32位整数
从内存中每次取数据时都会把这样一个cache line放到CPU cache中. 然而, Program A仅使用’a’和’b’, 因此取到的数据仅有一半被用到. cache line中所用到的数据仅占50%.
来看Program B, 它所用数据的内存布局如下图所示:

Program B的一个完整的cache line. 每个方块表示32位整数
这样, Program B每次取到的数据仅有’a’和’b’, 所有的数据都被用到, 利用率是100%.
这个示例给出了一个关键点: 程序的性能由开发者对内存访问范式的理解所决定, 如向量, 数组, 链表等. 但在所有这些情况中, 我们假定数据访问的开销和它的大小成正比. 然而, 内存访问中高层CPU cache的cache line单元带来了额外的复杂性.
数据密集型串行程序必须在数据大小超过cache大小时时考虑CPU cache的瓶颈. 高层cache经常被运行在相同处理器芯片上的进程和线程所共享, 因此可用cache一般要比物理cache要小. 对于共享内存系统中的多线程程序, 数据如何在cache间传递比数据大小更为重要.
More Examples¶
前面的示例演示了cache利用率不高会带来性能的严重下降, 然而, 仅通过观察无用的数据并不能经常定位性能下降的问题.
例如, 下面的两段代码有相同的无用数据, 但是仅通过交换两行代码的位置, Program D就要比Program C快60%:
1 2 3 4 5 6 7 8 9 10 11 | struct DATA
{
char a;
int b;
char c;
};
DATA *pMyData;
for (long i=0; i<36*1024*1024; i++) {
pMyData[i].a ++;
}
|
1 2 3 4 5 6 7 8 9 10 11 | struct DATA
{
int b;
char a;
char c;
};
DATA *pMyData;
for (long i=0; i<36*1024*1024; i++) {
pMyData[i].a ++;
}
|
这次是编译器的问题, 它会根据数据字段的类型和大小将它们放置到内存中. Program C的cache line如下图所示(白色方块表示由于数据对齐而浪费掉的内存空间):

Program C的cache line
Program D中内存组织如下图所示:

Program D的cache line
可以看到Program D的cache利用率明显比Program C要高, 因此性能更好.
数据结构的定义也不经常是问题所在. 要达到最好的性能, 关键是完全利用每次取得的cache line, 不好的访问逻辑同样会造成性能下降. 当然, 现代处理器都包含了硬件预取, 它会尝试预测后续要使用哪些数据, 并提前把它们取到cache中, 但这并不能覆盖所有情况.
下面是一个很好的示例:
1 2 3 4 5 6 7 | char * p;
p = new char[SIZE];
for (long x=0; x<sRowSize; x++) {
for (long y=0; y<nbRows; y++) {
p[x+y*sRowSize]++;
}
}
|
1 2 3 4 5 6 7 | char * p;
p = new char[SIZE];
for (long y=0; y<nbRows; y++) {
for (long x=0; x<sRowSize; x++) {
p[x+y*sRowSize]++;
}
}
|
如果我们(错误地)假定数据访问开销与其大小成正比, 那么就会认为这两段代码的性能是一样的. 然而Program F要比Program E快4倍. cache line跟我们玩了另一个把戏. 在C++中, 由于内存以行存储, 按行连续访问要比按列快4倍.
下图左边展示了Program E按列访问的顺序. 每次访问新的数据时, 将取得一个新的cache line(图中以蓝色方框表示, 随着每次访问向下移动). 右边展示了Program F按行访问的顺序, 每4次访问才需要取一个新的cache line:
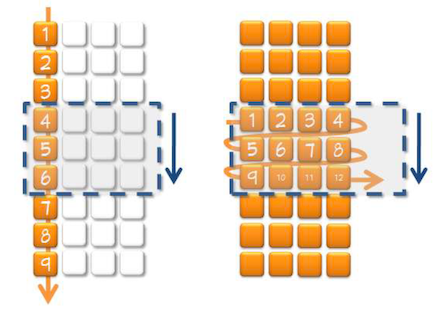
逐列访问(左)与逐行访问(右)的对比
最终, 由于对cache更有效的访问, Program F比Program E快了4倍.
Conclusion¶
本文仅通过示例演示了通过提高cache line利用率提升程序性能的几个技术, 还有很多其他cache相关的问题没有提到, 包括伪共享(false sharing), cache置换(cache thrashing), 非时态数据(non-temporal data)等, 它们也会导致性能的急剧下降. 通过本文, 读者需要了解数据访问开销不是与其大小成正比, 要明白cache对于数据密集型程序的性能的重要影响.
实际验证¶
为验证本文的正确性, 我分别在macbook(CPU: I5-5257U)和服务器(CPU: E5-2620v3)上对这些例子进行了编码测试. 使用了DPDK代码中的rdtsc代码来为程序计时, 单位为cycle数. 比如rtdsc代码为(在common.h中):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | #ifndef asm
#define asm __asm__
#endif
/** C extension macro for environments lacking C11 features. */
#if !defined(__STDC_VERSION__) || __STDC_VERSION__ < 201112L
#define RTE_STD_C11 __extension__
#else
#define RTE_STD_C11
#endif
#ifdef __APPLE__
#define FMT64 "%llu"
#else
#define FMT64 "%lu"
#endif
static inline uint64_t rte_rdtsc(void)
{
union {
uint64_t tsc_64;
RTE_STD_C11
struct {
uint32_t lo_32;
uint32_t hi_32;
};
} tsc;
asm volatile("rdtsc" :
"=a" (tsc.lo_32),
"=d" (tsc.hi_32));
return tsc.tsc_64;
}
|
Promgram A的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | #include <stdio.h>
#include <stdlib.h>
#include "common.h"
#define N 10*1024*1024
struct DATA {
int a;
int b;
int c;
int d;
};
int main(void) {
int i;
struct DATA* p = (struct DATA*) malloc(sizeof(struct DATA) * N);
uint64_t start, stop;
start = rte_rdtsc();
for(i=0; i<N; i++) {
p[i].a = p[i].b;
}
stop = rte_rdtsc();
printf(FMT64 "\n", stop - start);
return 0;
}
|
所有代码可在 https://github.com/zzqcn/storage/tree/master/code/c/cache_opt 中找到.
在实际机器测试前以 -O3 -march=native 选项编译代码, 然后用shell命令:
for ((i=0; i<10; i++)); do ./x; sleep 1; done
分别运行10次, 最后求平均值, 结果如下文图表所示. 其中,
- 示例1包含Program A和Program B, 分别命名为优化前和优化后
- 示例2包含Program C和Program D, 分别命名为优化前和优化后
- 示例3包含Program E和Program F, 分别命名为优化前和优化后
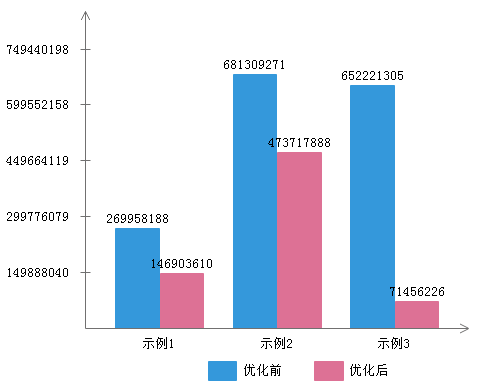
I5-5257U上的测试结果
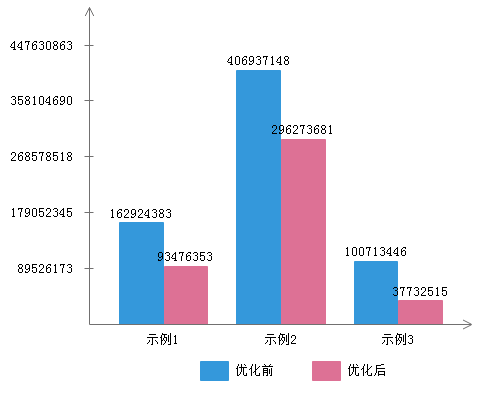
E5-2620v3上的测试结果