引言¶
本文更新于 2018.08.28
警告
此系列文章是<<深入浅出DPDK>>一本的读书笔记, 部分内容直接摘录自此书, 版权属于原作者(朱河清,梁存铭,胡雪焜,曹水等)和出版社(机械工业出版社)所有, 在此表示衷心感谢.
由来¶
单核 -> 多核
2005年以来CPU的发展已经从提升频率变为增加核心, ARM, MIPS, Power处理器也是如此. 同时高速网卡技术(如40Gbps, 100Gbps)也成为主流.
网络处理器 -> x86通用多核硬件平台
x86通用服务器上单核小包收发已达57Mp/s.
内核态+中断 -> 用户态+轮询
传统上的网卡驱动程序运行在内核态, 当时CPU运行速度远高于外设访问, 所以中断方式很有效; 但目前网卡速度已达40Gbps甚至100Gbps, CPU主频仍在3GHz左右, I/O超越CPU的运行速率, 是行业面临的技术挑战. 用轮询来处理高速端口开始成为必然, 构成了DPDK运行的基础.
硬件为主 -> 软件为主
之前的通信设备一般采用嵌入式的实现, 但x86的高性能可以降低成本, 提高硬件通用化, 令以软件为主体的网络设备成为可能. SDN / NFV / 虚拟化.
开源, 主流公司与厂商支持
DPDK最佳实践¶
基于IA多核处理器的dpdk, 可以很好地解决高性能数据包处理的问题, 而解决这个问题, 更多的是从工程优化角度的迭代和最佳实践的融合. 这些技术可大致总结如下:
轮询
避免中断上下文切换的开销, 缺点是CPU占用持续过高.
用户态驱动
避免内核态到用户态不必要的内存拷贝和系统调用, 对mbuf结构的重新定义, 对网卡DMA操作的重新优化可以获得更好的性能.
亲和性与独占
利用线程的CPU亲和绑定, 避免线程在不同核心间频繁切换; 限制某些核心不参与Linux系统调试, 可使线程独占该核心, 避免cache miss和多任务切换开销.
降低访存开销
有效利用cache, 利用大页内存降低TLB miss, 利用内存多通道的交错访问提高内存访问的带宽, 利用对于内存非对称性的感知避免额外的访存延迟等.
软件调优
一系列调优实践, 如cache line对齐, 避免多核间共享, prefetch, 多元数据批量操作等等.
利用IA新硬件技术
利用IA最新指令集及其他新功能, 如DDIO, SMID, 超标量(superscalar)技术, 数据层面和指令层面的深度并行化等.
充分挖掘网卡潜能
充分利用现代网卡所支持的分流(如RSS, FDIR等)和卸载(如Chksum, TSO等)等功能
dpdk框架¶
dpdk主要模块如下图所示:
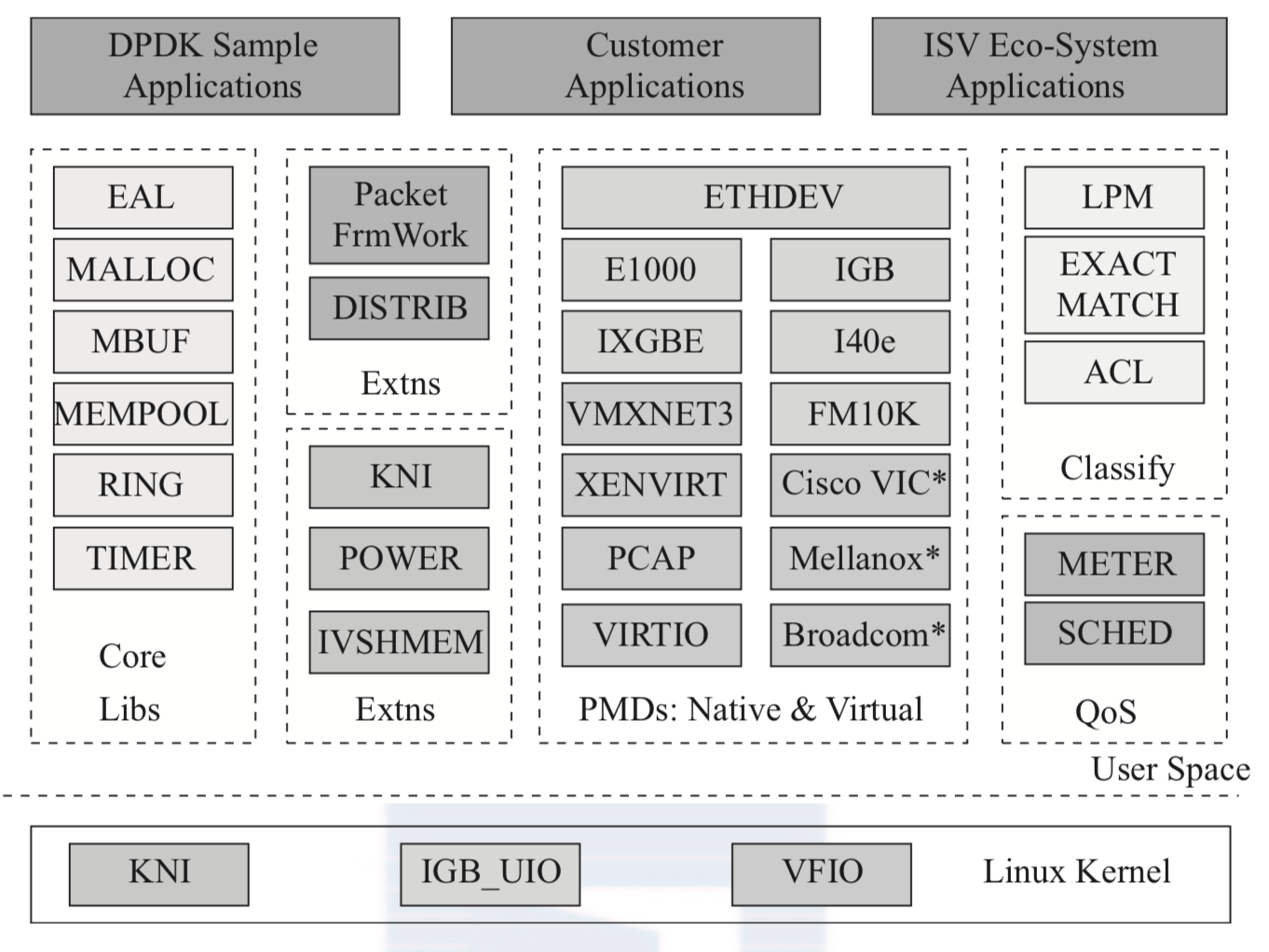
其中:
- Core Libs: 核心库, 提供系统抽象, 大页内存, 缓存池, 定时器及无锁环形队列等基础组件
- PMDs: 提供全用户态驱动, 以便通过轮询和线程绑定得到极高的网络吞吐, 支持各种本地和虚拟的网卡
- Classify: 支持精确匹配, 最长匹配(LPM)和通配符匹配(ACL), 提供常用包处理的查表操作
- QoS: 提供网络服务质量相关组件, 如限速(Meter)和调度(Sched)
- 其他: 为节能考虑的运行时频率调整(POWER), 与Linux内核建立快速通道的KNI(Kernel Network Interface), 多核流水线处理模型的基础Packet Framework和DISTRIB等
dpdk的应用¶
加速网络节点
网络功能虚拟化(NFV) - IA的CPU虚拟化技术和IO的的虚拟化技术; 支持各种I/O的SR-IOV接口; 支持标准virtio接口; 支持KVM, VMWARE, XEN的hypervisor, 容器技术
加速计算节点
以应用为中心的用户态协议栈
加速存储节点
SPDK